Жарознижуючі засоби для дітей призначаються педіатром. Але бувають ситуації невідкладної допомоги при лихоманці, коли дитині потрібно дати ліки негайно. Тоді батьки беруть на себе відповідальність і застосовують жарознижуючі препарати. Що дозволено давати дітям грудного віку? Чим можна збити температуру у дітей старшого віку? Які ліки найбезпечніші?
Існує кілька способів копіювання таблиці в базі даних MS SQL Server. Пропоную кілька варіантів створення копії таблиць. Який з них вибрати - залежить від структури таблиці, наявності в ній індексів, тригерів і т.п., а також бажання робити щось руками.
1. Ручний метод копіювання структури таблиці
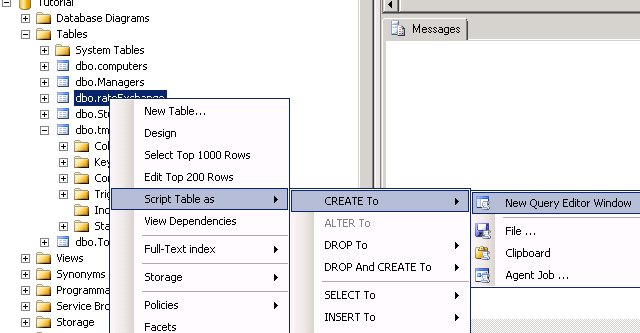
У Micrisoft SQL Management Studio вибрати базу, вибрати таблицю, натиснути правою кнопкою миші і вибрати пункти "Script Table as" -> "CREATE TO" -> "New Query Editor Window". У вікні запиту відкриється код для створення таблиці. У ньому потрібно вказати ім'я бази, в якій потрібно зробити копію таблиці, і нове ім'я, якщо база не змінюється. Як створити код для створення структури, що є таблиці, показано на малюнку нижче.
За допомогою цього способу будуть створені індекси таблиці, але не скопійовано тригери. Їх потрібно копіювати аналогічним способом.
Для копіювання даних в уже створену таблицю потрібно використовувати такий SQL запит:
INSERT into ..tmp_tbl_Deps SELECT * FROM ..tbl_Deps
2. Копіювання SQL таблиці запитом в одну строчку
Зробити копію структури таблицю і даних всередині однієї бази:
SELECT * into tmp_tbl_Dep FROM tbl_Deps
Скопіювати структури таблицю і її дані з однієї бази в іншу:
SELECT * into ..tmp_tbl_Deps FROM ..tbl_Deps
Мінус у такого рішення - чи не копіюються індекси.
А також: бекап SQL, бекап 1С.
Серверна 1С містить дані в базі даних, яка знаходиться на SQL сервері. Сьогодні ми розглядаємо варіант MS SQL 2005/2008.
Щоб дані не були втрачені в разі згорілого диска сервера або інших форс-мажорних ситуацій - необхідно з самого початку робити бекапи (backup).
Робити ручками кожен день Backup SQL бази 1С звичайно ніхто не хоче. Для цього є автоматичні засоби. Познайомимося з ними.
Налаштування Backup SQL
Налаштування Backup SQL для бази 1С нічим не відрізняється від настройки бекапа для будь-якої іншої бази даних.
Для настройки запустіть MS SQL Management Studio. Ця програма знаходиться в групі програм MS SQL.
Додавання завдання бекапа SQL бази 1С
Завдання автоматичного бекапа баз SQL знаходяться в гілці Management / Maintenance plans.

Щоб додати нове завдання бекапа клацніть на групу Maintenance plans правою кнопкою миші і виберіть New Maintenance Plan.

Введіть назву завдання. Назва має значення тільки для Вас. Про всяк випадок краще використовувати англійські символи.
Налаштування завдання бекапа SQL бази 1С
Відкриється редактор завдань. Зверніть увагу - завдання можуть робити різні операції з базою даних, а не тільки бекапи.
Список варіантів операцій виведений зліва внизу. Виберіть Back Up Database Task подвійною кнопкою миші або просто перетягніть вправо.

Зверніть увагу на стрілочку. Ви можете перетягнути кілька різних або однакових операцій та зв'язати їх стрілочками. Тоді буде виконуватися відразу кілька завдань у певній Вами послідовності.

У вікні настройки виберіть потрібні бази SQL 1С (можна відразу кілька або по одній).

Виберіть місце збереження бекапа бази SQL 1С. Необхідно вибрати фізично інший вінчестер. Організаційно можна поставити галочку «Створити папки».
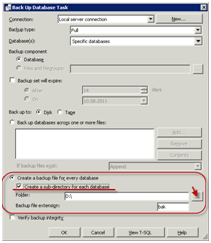
Тепер налаштуємо розклад backup. Розклад backup за замовчуванням додалося саме. Але Ви можете додати кілька розкладів (наприклад, одне - щоденне, одне - щотижневе і т.п.). Натисніть кнопку, щоб запланувати backup.

На скріншоті приклад щоденного Backup SQL бази 1С в 3 ночі.

Щоб розклад backup в списку було красиво-зрозумілим, його можна змінити.

Збереження завдання бекапа SQL бази 1С
Натисніть записати. Завдання з'явиться зліва в списку.
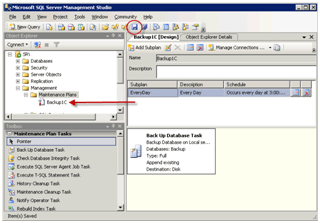
Це важливо! Перевірте правильність створення завдання Backup SQL бази. Для цього натисніть на завданні правою кнопкою і виберіть Execute.
В результаті повинен з'явиться файл бекапа за вказаним шляхом. Якщо щось не так - видаліть завдання (Del) і почніть з початку.
Дана стаття присвячена рішенням для відновлення MS SQL. Постараємося розглянути основні моменти і важливі деталі, які необхідно врахувати, при плануванні і виборі рішення для відновлення бази даних MS SQL.
В рамках планування аварійного відновлення MS SQL особливий інтерес представляють два параметри: допустимий час відновлення (recovery time objective - RTO) і допустима точка відновлення (recovery point objective - RPO).
RPO іншими словами, це період часу з моменту останнього резервного копіювання до моменту інциденту, за який буде втрачено не критичний обсяг даних (інформації). RTO - це допустимий час, за яке необхідно відновити працездатність сервісу / системи з моменту інциденту. Обидва параметра мають змінне значенняі залежать від вимог до тієї чи іншої системи. Тому для виконання, встановлених RPO і RTO необхідно мати відповідний план резервного копіювання. На прикладі, проведемо аналіз можливих аварійних інцидентів і спробуємо виділити точки відмови нашого SQL сервера і способи їх вирішення:
- апаратний збій, фізичний вихід сервера з ладу: диски, CPU, системна плата, блок живлення і т.д.
- програмний збій: операційна система, база даних
Для кожного позначеного інциденту є цілий комплекс заходів, що дозволяє уникнути наслідки інциденту.
HIGH AVAILABILITY MS SQL
При високих вимогах до RPO і RTO (секунди / хвилини) єдиним рішенням для забезпечення відмовостійкості MS SQL є організація технології високої доступності сервера (High Availability):
- Вбудованими засобами MS SQL і ОС Windows Serverми можемо досягти високої доступності (High Availability) за рахунок реалізації отказоустойчивого кластера Windows Server Failover Cluster (WSFC) в тому числі і з застосуванням технології AlwaysOn. Відмов кластер складається як мінімум з двох вузлів / серверів. При збої активного сервера, відбувається аварійне перемикання на інший доступний сервер, він стає активним. При цьому всі служби, які розміщувалися на сервері автоматично або вручну переносяться на інший доступний вузол.
- У випадки, з віртуальною машиною MS SQL високу доступність можна забезпечити c допомогу засобів віртуалізації VMware HA-cluster або Hyper-V High Availability. В цьому випадку при виході з ладу фізичного сервера, дозволяє автоматично запустити віртуальну машину на іншому сервері кластера.
Обидва способи можуть бути реалізовані як окремо, так і спільно, якщо в цьому є необхідність. Кластеризація більшою мірою розрахована для оперативного усунення апаратного збою.
Переваги High Availability MS SQL:
- миттєве перемикання з Ноди на ноду, без простою
- без залежності від фізичних серверів
- дозволяє проводити обслуговування серверів без перерви в роботі з базою даних
Недоліки High Availability MS SQL:
- реалізації вимагає додаткової інфраструктури та ресурсів
- висока вартість рішення за ліцензіями та обладнання
- більш складне і висококваліфікованих обслуговування
BACKUP MS SQL
У випадках, коли вимоги до RTO і RPO невисокі і потреба в High Availability (кластеризації) відсутня, для забезпечення відмовостійкості баз даних MS SQL на фізичному або віртуальному сервері необхідною умовоює наявність резервної копії. Для цього можна задіяти вбудовані функції SQL Server або використовувати окремі спеціалізовані системи, що підтримують різні способирезервного копіювання MS SQL, наприклад:
Дані системи допоможуть уникнути як апаратних, так і програмних збоїв в роботі сервера бази даних.
Після розрахунку значень RTO і RPO можна перейти до планування конфігурації SQL сервера. Для досягнення цих значень ми можемо використовувати як технології високої доступності, перераховані вище, так і backup баз даних.
Регламент backup MS SQL
- Резервні копії повинні знаходитися на різних фізичних носіях з вихідними файлами бази даних
- Використовуйте тестовий сервер (пісочниця) для перевірки процедури відновлення резервних копій
- виконуйте щоденне
- Робіть якомога частіше. Вони займають набагато менший обсяг в сховище і ще більше скорочують ризик втрати даних
- Як можна частіше робіть резервні копії журналів транзакцій. Журнали транзакцій містять всі останні дії, Що відбулися в базі даних. Журнали можна використовувати для відновлення бази даних на певний момент часу, і це є найбільшою перевагою. Резервні копії журналу транзакцій можуть виконуватися під час роботи системи. Якщо частота нових даних, що створюються в вашій базі даних, дуже висока, то можна робити резервні копії журналу транзакцій кожні 10 хвилин, в той час як для інших баз даних, які менш активні, таке резервне копіювання може виконуватися кожні 30 або 60 хвилин
- Робіть резервні копії системних баз даних MS SQL: server, master, model та msdb. Ці бази даних абсолютно необхідні, так як містять конфігурацію системи, а також інформацію про завдання SQL Server, яку необхідно буде відновити в разі повного відновлення системи
НАСТРОЙКА РЕЗЕРВНОГО копіювання MS SQL ЗА ДОПОМОГОЮ BACKUP EXEC
Backup Execпропонує три методи резервного копіювання MS SQL: Full, Differential і Full Copy-only. Метод Full виконує повне резервне копіювання всієї бази даних, а Differential виконує резервне копіювання тільки зміни блоків в базі даних з моменту останнього повного резервного копіювання. Метод Full Copy-only ідентичний повного резервного копіювання, але тільки він не впливає на наступні завдання диференціального резервного копіювання.
Розглянемо кожен випадок більш докладно для цього створимо в системі нове завдання для резервного копіювання основний і системних баз даних.
Потім, в настройках параметрів (опції) вибрати тип завдання (спочатку налаштувати Full потім Differential backup).

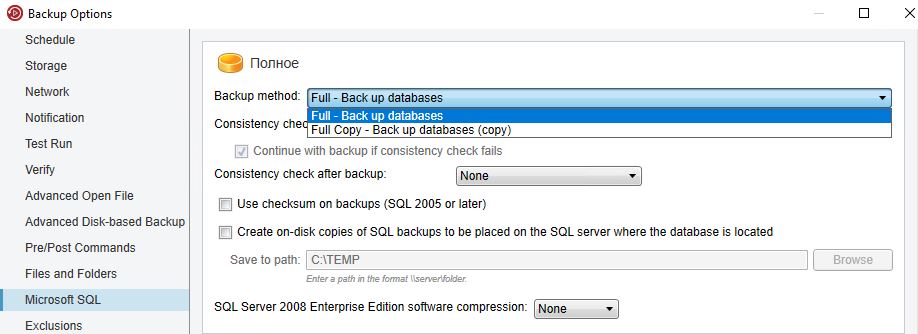
У Backup Exec є дуже важлива і корисна функція«Перевірка цілісності бази до і після виконання резервного копіювання» (Consistency check before / after backup), є на вибір чотири варіанти:
- не проводити перевірку
- повна перевірка, без урахування індексів
- повна перевірка з урахуванням індексів
- тільки фізична перевірка

Для настройки differential backup необхідно (аналогічно job full backup) спочатку додати нове завдання Job Differential, а потім на вкладці Microsoft SQL вибрати один з методів резервного копіювання.

В даному списку в першу чергу цікавить «Differential - Backup up database changes since the last full»(Створення диференціальної резервної копії на підставі повної). Так само можливий варіант створення диференціальної резервної копії (на рівні блоків) з подальшою конвертацією в віртуальну машину «Differential (block-level) - Backup up database changes since the last full - use with convert to virtual machine job».
Ще одним важливим параметром є «Log - Back up and truncate transaction log»для резервного копіювання журналу транзакцій MS SQL.
Ми розглянули основні моменти резервного копіювання MS SQL. Звертаємо увагу, що резервне копіювання є частиною загального плану аварійного відновлення (DRP), тому, перед плануванням резервного копіювання, необхідно провести повний аналіз систем і інфраструктури, для забезпечення RPO і RTO. А якщо є можливість виконати планування DRP при розробці системи, це допоможе виключити багато проблем і, можливо, здешевить експлуатацію системи.
Використовувана в статті інформація взята з офіційних джерел.
Адміністратори БД діляться на тих, хто робить бекапи, і тих, хто буде робити бекапи.
Вступ
У цій статті описано звичайнісіньке резервне копіювання ІБ 1С за допомогою інструментів MS SQL Server 2008 R2, пояснено чому слід робити саме так, а не інакше, і розвіяно кілька міфів. У статті досить багато посилань на документацію MS SQL, ця стаття скоріше огляд механізмів резервного копіювання, ніж всеосяжне керівництво. Але для тих, хто стикається з цим завданням вперше, дані прості і покрокові інструкції, Які застосовні до простих ситуацій. Стаття призначена не для гуру адміністрування, гуру і так все це знають, але передбачається, що читач здатний сам встановити MS SQL Server і змусити це чудо ворожої техніки створити в своїх надрах базу даних, яку в свою чергу він же здатний змусити зберігати дані 1С.
Я вважаю команду TSQL BACKUP DATABASE (і її брата BACKUP LOG) по суті єдиним засобом резервного копіювання баз 1С, що використовують MS SQL Server в якості СУБД. Чому? Давайте розглянемо, які у нас способи взагалі є:
| як | добре | погано | Разом |
| Вивантаження в dt | Дуже компактний формат. | Довго формується, вимагає монопольного доступу, не зберігає частину малозначних даних (таких як настройки користувачів в ранніх версіях), довго розгортається. | Це не стільки спосіб резервного копіювання, скільки спосіб перенесення даних з одного середовища в іншу. Ідеальний для вузьких каналів. |
| копіювання файлів mdfі ldf | Дуже зрозумілий спосіб для початківців адміністраторів. | Вимагає звільнення файлів бази даних від блокування, а це можливо, якщо база відключена (команда take offline контекстного меню), від'єднана (detach) або просто зупинений сервер. Очевидно, що користувачі в цей час працювати не зможуть. | Цей спосіб має сенс застосовувати тоді і тільки тоді, коли вже сталася аварія, щоб при спробах відновлення хоча б мати можливість повернутися до того варіанту, з якого почалося відновлення. |
| Резервне копіювання засобами ОС або гипервизора | Зручний спосіб для середовищ розробки і тестування. | Не завжди дружить з цілісністю даних. Ресурсномісткий спосіб. | Може обмежено застосовуватися для розробки. У продуктовій середовищі практичного сенсу не має. |
| Резервне копіроавніе засобами MS SQL | Не вимагає простоїв. Дозволяє відновити цілісний стан на довільний момент, якщо заздалегідь про це потурбуватися. Відмінно автоматизується. Економний за часом і іншим ресурсам. | Не дуже компактний формат. Не всі вміють користуватися цим способом в необхідній мірі. | Для продуктових середовищ - основний інструмент. |
Основні складності при використанні резервного копіювання вбудованими засобами MS SQL виникають через елементарне нерозуміння принципів роботи. Це пояснюється частково великої лінню, почасти відсутністю простого і зрозумілого роз'яснення на рівні "готових рецептів" (хм, скажімо так, мені не зустрічалося), та ще й посилюється ситуація міфосоветамі "недогуру" на форумах. Що робити з лінню я не знаю, а от пояснити основи резервного копіювання спробую.
Що і навіщо зберігаємо?
Давним-давно в далекій галактиці існував такий продукт інженерно-бухгалтерської думки, як 1С: Підприємство 7.7. Мабуть через те, що перші версії 1С: Підприємства розроблялися для використання популярного формату файлів dbf, Його SQL-версія не зберігала в базі даних достатньо інформації для того, щоб вважати резервне копіювання MS SQL повноцінним, та ще й при кожній зміні структури порушувалися умови роботи повної моделі відновлення, тому доводилося йти на різні хитрощі, щоб змусити систему резервного копіювання виконувати свою основну функцію. Але, з тих пір, як з'явилася версія 8 адміністратори баз даних нарешті змогли розслабитися. Штатні засоби резервного копіювання дозволяють створити повну і цілісну систему резервних копій. Чи не входить в резервне копіювання тільки журнал реєстрації і деякі дрібниці типу налаштувань положення форм (в старих версіях), але це втрата цих даних на функціональності системи в не позначається, хоча безумовно резервні копії журналу реєстрації робити правильно і корисно.
А навіщо взагалі нам потрібно резервне копіювання? Хм. На перший погляд дивне запитання. Ну, напевно, по-перше, щоб мати можливість розгорнути копію системи і по-друге відновити систему при збої? На рахунок першого я згоден, а от друге призначення - перший міф резервного копіювання.
Резервне копіювання - це останній рубіж забезпечення схоронності системи.Якщо адміністратору бази даних доводиться відновлювати продуктову систему з резервних копій, значить, з великою ймовірністю було допущено безліч грубих помилок в організації робіт. Не можна ставитися до резервного копіювання, як до основного способу забезпечення цілісності даних, немає, це скоріше ближче до системи пожежогасіння. Система пожежогасіння необхідна. Вона повинна бути налаштована, перевірена і працездатна. Але якщо вона спрацювала, то це саме по собі є серйозним ПП з масою негативних наслідків.
Для того, щоб резервне копіювання застосовувалося тільки "в мирних" цілях, використовуйте для забезпечення працездатності та інші засоби:
- Забезпечте фізичну безпеку серверів: пожежі, затоплення, погане електроживлення, прибиральниці, будівельники, метеорити і дикі тварини - все вони тільки і чекають за рогом, щоб знищити вашу серверну.
- Відповідально ставтеся до погроз інформаційної безпеки.
- Кваліфіковано вносите зміни в систему і заздалегідь максимально переконайтеся, що ці зміни не призведуть до погіршень. Крім плану внесення змін бажано мати і план "що робити, якщо все піде не так".
- Активно використовуйте технології підвищення доступності та надійності системи замість того, щоб потім розгрібати наслідки аварій. Для MS SQL слід звернути на наступні можливості:
- Використання кластерів MS SQL (хоча, якщо чесно, я вважаю, це одним з найбільш дорогих і непотрібних способів зайняти адміністратора БД для систем які не потребують 24х7)
- Віддзеркалення бази даних (в синхронному і асинхронному режимі в залежності від вимог доступності, продуктивності і вартості)
- Доставка журналів транзакцій
- Реплікація засобами 1С (розподілені бази даних)
Залежно від вимог доступності системи і від бюджету, виділеного на ці цілі, цілком можна вибрати рішення, які дозволять на 1-2 порядки скоротити час простою і відновлення при збоях. Не потрібно боятися технологій підвищення доступності: вони досить прості для того, щоб їх вивчити за кілька днів при базових знаннях MS SQL.
Але, незважаючи ні на що, резервне копіювання все ж таки необхідно. Це той самий запасний парашут, який ви зможете використовувати, коли всі інші засоби порятунку відмовлять. Але, як і справжній запасний парашут, для цього:
- ця система повинна бути заздалегідь правильно і кваліфіковано налаштована,
- фахівець користується системою повинен мати теоретичні та практичні навички її застосування (регулярно підкріплені),
- система повинна складатися з максимально надійних і простих компонент(Це ж наша остання надія).
Базова інформація про зберігання і обробки даних MS SQL
Дані в MS SQL зазвичай зберігаються в файлах даних (далі ФД - скорочення не загальновживане, в даній статті буде ще декілька не дуже поширених скорочень) з розширеннями mdf або ndf. Крім цих файлів є ще журнали транзакцій (ЗТ), які зберігаються в файлах з розширенням ldf. Нерідко починаючі адміністратори безвідповідально і легковажно ставляться до ЗТ, як щодо продуктивності, так і по відношенню до надійності зберігання. Це дуже груба помилка. Насправді, скоріше навпаки, якщо є надійно функціонуюча система резервного копіювання та на відновлення системи можна виділити багато часу, то можна зберігати дані на швидкому, але вкрай ненадійному RAID-0, але тоді ЗТ повинні зберігатися на окремому надійному і продуктивному ресурсі (хоча б на RAID-1). Чому так? Давайте розглянемо докладніше. Відразу обмовлюся, що виклад дещо спрощено, але досить для початкового розуміння.
У ФД зберігаються дані сторінками по 8 кілобайт (які об'єднані в екстенти по 64 кілобайт, але це не суттєво). MS SQL не гарантує, Що відразу після виконання команди зміни даних, ці зміни потраплять в ФД. Ні, просто сторінка в пам'яті позначається як "вимагає збереження". Якщо у сервера достатньо ресурсів, то незабаром ці дані виявляться на диску. Причому, сервер працює "оптимістично" і якщо ці зміни відбуваються в транзакції, то вони цілком можуть потрапляти на диск до фіксації транзакції. Тобто в загальному випадку, при активній роботі ФД містить розрізнені шматки недописаних даних і незавершених транзакцій, для яких невідомо, чи будуть вони скасовані або зафіксовані. Є спеціальна команда "CHECKPOINT", яка вказує серверу, що потрібно "прямо зараз" скинути все незбережені дані на диск, але область застосування цієї команди досить специфічна. Досить сказати, що 1С її не використовує (я не стикався) і розуміти, що під час роботи зазвичай ФД не перебуває у цілісному стані.
Щоб впоратися з цим хаосом нам якраз і потрібний ЗТ. У нього пишуться такі події:
- Інформація про старт транзакції і її ідентифікатор.
- Інформація про факт фіксації або скасування транзакції.
- Інформація про всі зміни даних в ФД (грубо кажучи, що було і що стало).
- Інформація про зміну самого ФД або структури бази даних (збільшення файлів, зменшення файлів, виділення і звільнення сторінок, створення і видалення таблиць і індексів)
Вся ця інформація пишеться із зазначенням ідентифікатора транзакції в якій вона відбулася і в достатньому обсязі щоб зрозуміти як зі стану до цієї операції перейти до стану після цієї операції і навпаки (виняток - модель відновлення з неповним протоколированием).
Важливо, що ця інформація пишеться на диск відразу. Поки інформацію не записана в ЗТ, команда не вважається виконаним. У нормальній ситуації, коли розмір ЗТ достатнього обсягу і коли він не сильно фрагментований, записи в нього пишуться послідовно невеликими записами (не обов'язково кратні 8 кб). У журнал транзакцій потрапляють дані тільки дійсно необхідні для відновлення. Зокрема НЕпотрапляє інформація про те, який текст запиту привів до модифікацій, який план виконання був у цього запиту, який користувач його запустив та інша непотрібна для відновлення інформація. Певне уявлення про структуру даних журналу транзакцій може дати запит
Select * from :: fn_dblog (null, null)
Через те, що жорсткі диски значно ефективніше працюють з послідовної записом, ніж з хаотичним потоком команд на читання і запис і через те, що команди SQL будуть чекати моменту закінчення записи в ЗТ, виникає наступна рекомендація:
Якщо є хоч найменша можливість, то в продуктовій середовищі ЗТ повинні розташовуватися на окремих (від всього іншого) фізичних носіях, бажано з мінімальним часом доступу для послідовного запису і з максимальною надійністю. Для простих систем цілком підійде RAID-1.
Якщо транзакція скасовується, то все вже внесені зміни сервер поверне в попередній стан. Саме тому
Скасування транзакції в MS SQL Server зазвичай триває можна порівняти з сумарною тривалістю операцій зміни даних самої транзакції. Намагайтеся не скасовувати транзакції або приймати рішення про скасування якомога раніше.
Якщо сервер з якихось причин несподівано припинить роботу, то при повторному запуску буде проаналізовано, які дані в ФД не відповідають цілісного стану (незаписані, але зафіксовані транзакції і записані, але скасовані транзакції) і ці дані будуть відкориговані. Тому якщо ви, наприклад запустили перестроювання індексів великий таблиці і провели перезапуск сервер, то при повторному запуску піде значний час на відкат цієї транзакції, причому перервати цей процес можливості немає.
Що відбувається коли ЗТ дійшов до кінця файлу? Все просто - якщо є звільнене місце на початку, то він почне писати в вільне місцена початку файлу до зайнятого місця. Як закільцьованих магнітна стрічка. Якщо місця на початку немає, то сервер зазвичай спробує розширити файл журналу транзакцій, при цьому для сервера виділений новий шматок є новим віртуальним файлом журналу транзакцій, яких у фізичному файлі транзакцій може бути багато, але це вже до резервного копіювання відноситься мало. Якщо у сервера не вийде розширити файл (закінчилося місце на диску або заборонено настройками розширювати ЗТ), то поточна транзакція скасується з помилкою 9002.
Упс. А що ж треба зробити щоб місце в ЗТ завжди було? Ось тут ми підійшли до системи резервного копіювання та до моделей відновлення. Для скасування транзакцій і для відновлення коректного стану сервера в разі раптового вимкнення необхідно зберігати в ЗТ записи, починаючи з моменту старту самої ранньої з відкритих транзакцій. Цей мінімум пишеться і зберігається в ЗТ обов'язково. Незалежно від погоди, налаштувань сервера і бажання адміна. Сервер не може допустити, щоб цієї інформації не було. Тому, якщо відкрити в одному сеансі транзакцію, а в інших виконувати різні дії, то журнал транзакцій може несподівано закінчитися. Найбільш ранню транзакцію можна виявити командою DBCC OPENTRAN. Але це тільки необхідний мінімум інформації. Подальше залежить від моделі відновлення. У SQL Server їх три:
- Simple (Проста)- зберігається тільки необхідний для життя залишок ЗТ.
- Full (Повна)- зберігається весь ЗТ з моменту останнього резервного копіювання журналу транзакцій. Зверніть увагу, чи не з моменту повного бекапа!
- Bulk logged (С неповним протоколированием)- частина (дуже невелика зазвичай частина) операцій записуються в дуже компактному форматі (по суті тільки запис, що змінена така-то сторінка файлу даних). В іншому ідентична Full.
З моделями відновлення пов'язано кілька міфів.
- Simple дозволяє знизити навантаження на дискову підсистему. Це не так. пишеться рівно стільки ж, скільки при Bulk logged, тільки вважається вільним набагато раніше.
- Bulk logged дозволяє знизити навантаження на дискову підсистему. Для 1С це майже не так. По суті одна з небагатьох операцій, яка може без додаткових танців з бубном підпадати під мінімальне протоколювання - завантаження даних з вивантаження в форматі dt і реструктуризація таблиць.
- При використанні моделі Bulk logged якісь операції не потрапляють в резервну копію журналу транзакцій і вона не дозволяє відновити стан на момент цієї резервної копії. Це не зовсім так. Якщо операція відноситься до мінімально протоколюються, то в резервну копію потраплять поточні сторінки з даними і буде можливість "програти" журнал транзакцій до кінця (хоча і не можна на довільний момент часу, якщо є мінімально протоколюються операції).
Модель Bulk logged для баз 1С використовувати майже безглуздо, тому далі ми її не розглядаємо. А ось вибір між Full і Simple розглянемо докладніше в наступній частині.
- Структура журналу транзакцій
-
- Моделі відновлення і управління журналом транзакцій
- Управління журналом транзакцій
- Використання резервних копій журналів транзакцій
Принцип дії резервного копіювання в моделях відновлення Simple і Full
За типом формування резервні копії бувають трьох видів:
- Full(Повна)
- Differential(Диференційна, різницева)
- Log(Резервна копія журналів транзакцій, враховуючи, те, наскільки часто цей термін використовується, будемо скорочувати до РКЖТ)
Тут треба не заплутатися: повна модель відновлення і повна резервна копія - істотно різні речі. Для того щоб їх не сплутати, нижче я буду використовувати англійські терміни для моделі відновлення і російськомовні для видів резервних копій.
Повна і диференціальна копія працюють однаково для Simple і Full. Резервна копія журналів транзакцій повністю відсутня в Simple.
Повна резервна копія
Дозволяє відновити стан бази даних на деякий момент часу (на той в який розпочато формування резервної копії). Складається з посторінковою копії використовуваної частини файлів даних і активного шматка журналу транзакцій за той час поки формувалася резервна копія.
Разностная резервна копія
Зберігає сторінки даних, що змінилися з моменту останньої повної резервної копії. При відновленні потрібно спочатку відновити повну резервну копію (у режимі NORECOVERY, приклади будуть наведені нижче), потім можна до отриманої "заготівлі" застосувати будь-яку з наступних різницевих копій, але, звичайно тільки з тих, які зроблені до наступної повної резервної копії. За рахунок цього можна значно знизити обсяг дискового простору для зберігання резервної копії.
Важливі моменти:
- Без попередньої повної резервної копії разностная копія марна. Тому бажано зберігати їх десь поруч один з одним.
- Кожна наступна разностная копія буде зберігати всі сторінки, що входять в попередню разностную резервну копію, зроблену після попередньої повної (хоча, можливо, вже з іншим вмістом). Тому кожна наступна разностная копія більше попередніх, поки знову не зробити повну копію (якщо це і порушується, то тільки через алгоритмів стиснення)
- Для відновлення на якийсь момент досить останньоїповна резервна копія на цей момент і останньоїразностной копії на цей момент. Проміжні копії для відновлення не потрібні (хоча вони можуть бути потрібні для вибору моменту відновлення)
РКЖТ
Містить копію ЗТ за деякий період. Зазвичай з моменту минулого РКЖТ до моменту формування поточної РКЖТ. РКЖТ дозволяє з відновленої в режимі NORECOVERY копії на будь-який момент часу, що входить в період відновлюваної копії ЗТ, відновити стан на будь-який інший час після цього часу, що входить в інтервал відновлюваної резервної копії. При формуванні резервної копії зі стандартними параметрами, місце в файлі журналу транзакцій вивільняється (до моменту останньої відкритої транзакції).
Очевидно, що РКЖТ не має сенсу в моделі Simple (тоді ЗТ містить лише інформацію з моменту останньої незакритих транзакції).
При використанні РКЖТ виникає важливе поняття - безперервний ланцюжок РКЖТ. Цей ланцюжок може перервати або втрата деяких резервних копій цього ланцюжка, або переклад бази даних в Simple і назад.
Увага: набір РКЖТ по суті марний, якщо він не є безперервним ланцюжком, причому момент початку останнього успішного повного або різницевого резервного копіювання повинен бути всерединіперіоду цього ланцюжка.
Часті помилки і міфи:
- "РКЖТ містить дані журналу транзакцій від моменту попереднього повного або різницевого бекапа".Ні це не так. РКЖТ містить і на перший погляд непотрібні дані між попередньою РКЖТ і подальшим повним бекапом.
- "Повний або різницевий бекап повинні призводити до звільнення місця всередині журналу транзакцій".Ні це не так. Повний і різницевий бекап не чіпають ланцюжок РКЖТ.
- ЗТ потрібно перідіческі чистити вручну, зменшувати, шрінкать.Ні, не треба і навіть навпаки - небажано. Якщо звільняти ЗТ між РКЖТ, то буде порушена ланцюжок РКЖТ, потрібна для відновлення. А постійні зменшення / розширення файлу приведуть до його фізичної та логічної фрагментації.
Як це працює в simple
Нехай є база даних в 1000 ГБ. Кожен день база приростає на 2 ГБ, при цьому змінюється 10 ГБ старих даних. Зроблені наступні резервні копії
- Повна копія F1 від 0:00 1 лютого (обсяг 1000 ГБ, стиснення для простоти картини не враховуємо)
- Разностная копія D1.1 від 0:00 2 лютого (об'єм 12 ГБ)
- Разностная копія D1.2 від 0:00 3 лютого (обсяг 19 ГБ)
- Разностная копія D1.3 від 0:00 4 лютого (обсяг 25 ГБ)
- Разностная копія D1.4 від 0:00 5 лютого (обсяг 31 ГБ)
- Разностная копія D1.5 від 0:00 6 лютого (обсяг 36 ГБ)
- Разностная копія D1.6 від 0:00 7 лютого (обсяг 40 ГБ)
- Повна копія F2 від 0:00 8 лютого (обсяг 1014 ГБ)
- Разностная копія D2.1 від 0:00 9 лютого (об'єм 12 ГБ)
- Разностная копія D2.2 від 0:00 10 лютого (обсяг 19 ГБ)
- Разностная копія D2.3 від 0:00 11 лютого (обсяг 25 ГБ)
- Разностная копія D2.4 від 0:00 12 лютого (обсяг 31 ГБ)
- Разностная копія D2.5 від 0:00 13 лютого (обсяг 36 ГБ)
- Разностная копія D2.6 від 0:00 14 лютого (обсяг 40 ГБ)
За допомогою цього набору ми можемо відновити дані на момент 0:00 будь-якого із днів з 1 по 14 лютого. Для цього нам потрібно взяти повну копію F1 для тижні 1-7 лютого або повну копію F2 для 8-14 лютого, відновити її в режимі NORECOVERY і потім застосувати разностную копію потрібного дня.
Як це працює в full
Нехай у нас є такий же набір резервних повних і різницевих резервних копій, як в попередньому прикладі. На додаток до цього є наступні РКЖТ:
- РКЖТ 1 за період з 12:00 31 січня до 12:00 2 лютого (близько 30 ГБ)
- РКЖТ 2 за період з 12:00 2 лютого по 12:00 4 лютого (близько 30 ГБ)
- РКЖТ 3 за період з 12:00 4 лютого до 12:00 6 лютого (близько 30 ГБ)
- РКЖТ 4 за період з 12:00 6 лютого до 12:00 7 лютого (близько 30 ГБ)
- РКЖТ 5 за період з 12:00 8 лютого до 12:00 10 лютого (близько 30 ГБ)
- РКЖТ 6 за період з 12:00 10 лютого до 12:00 12 лютого (близько 30 ГБ)
- РКЖТ 7 за період з 12:00 12 лютого до 12:00 14 лютого (близько 30 ГБ)
- РКЖТ 8 за період з 12:00 14 лютого до 12:00 16 лютого (близько 30 ГБ)
Зверніть увагу:
- Розмір РКЖТ буде приблизно постійним.
- Резервні копії ми можемо робити рідше, ніж різницеві або повні, а можемо і частіше, тоді вони будуть менше за розміром.
- Тепер ми можемо відновити стан системи на будь-який момент з 0:00 1 лютого, коли у нас є найраніша повна копія до 12:00 16 лютого.
У найпростішому випадку нам для відновлення знадобляться:
- Остання повна копія до моменту відновлення
- Остання разностная копія до моменту відновлення
- Все РКЖТ, від момена останньої разностной копії до моменту відновлення
- Повна копія F2 від 0:00 8 лютого
- Разностная копія D2.2 від 0:00 10 лютого
- РКЖТ 6 за період з 12:00 10 січня до 12:00 12 лютого
Спочатку буде відновлена F2, потім D2.2, потім РКЖТ 6 до моменту 13:13:13 10 лютого. Але суттєва перевага Full моделі в тому, що у нас з'являється вибір - використовувати останню повну або разностную копію або НЕ останню. Наприклад, якби виявилося, що копія D2.2 була зіпсована, а нам треба відновити на момент до 13:13:13 10 лютого, то для моделі Simple це б означало, що ми можемо відновити дані тільки на момент D2.1. При Full - "DON" T PANIC ", у нас є такі можливості:
- Відновити F2, потім потім D2.1, потім РКЖТ 5, потім потім РКЖТ 6 до моменту 13:13:13 10 лютого.
- Відновити F2, потім РКЖТ 4, потім РКЖТ 5, потім потім РКЖТ 6 до моменту 13:13:13 10 лютого.
- Або взагалі відновити F1 і прогнати все РКЖТ до РКЖТ 6 до моменту 13:13:13 10 лютого.
Як видно, повна модель надає нам більший вибір.
А тепер уявімо, що ми дуже хитрі. І за пару днів до збою (13:13:13 10 лютого.) Знаємо, що збій буде. Ми відновлюємо на сусідньому сервері базу даних повної резервної копії, залишаючи можливість донакативать наступні стану різницевими копіями або РКЖТ, т. Е. Залишили в режимі NORECOVERY. І кожен раз відразу після формування РКЖТ застосовуємо її до цієї резервної базі, залишаючи в режимі NORECOVERY. Ого! Та на відновлення бази даних у нас тепер піде всього 10-15 хвилин, замість того, щоб відновлювати величезну базу! Вітаю, ми заново винайшли механізм доставки журналів, один із способів зниження часу простоїв. Якщо так передавати дані не раз в період, а постійно, то вийде вже віддзеркалення, причому якщо база-джерело чекає поки база-дзеркало оновиться, то це синхронне віддзеркалення, якщо не чекає, то асинхронне.
Детальніше про засоби високої доступності можна прочтітать в довідці:
- Високий рівень доступності (компонент Database Engine)
- Загальні відомості про рішення з високим рівнем доступності
- Високий рівень доступності. Взаємодія і спільна робота
Інші аспекти резервного копіювання
Цей розділ можна сміливо припустити, якщо вам набридла теорія і руки сверблять випробувати налаштування резервного копіювання.
файлові групи
1С: Підприємство по суті не вміє працювати з файловими групами. Є єдина файлова група і все. Насправді програміст або адміністратор бази даних MS SQL здатний деякі таблиці, індекси або навіть шматки таблиць і індексів покласти в окремі файлові групи (в найпростішому варіанті - в окремі файли). Це потрібно або для того, щоб прискорити доступ до якихось даними (поклавши на дуже швидкі носії), або навпаки, пожертвувавши швидкістю помістити на більш дешеві носії (наприклад, маловикористовувані але об'ємні дані). При роботі з файловими групами є можливість робити їх резервні копії окремо, також окремо можна і відновлювати, але потрібно врахувати, що всі файлові групи доведеться "наздогнати" до одного моменту накочуванням РКЖТ.
файли даних
Якщо приміщенням даних в різні файлові групи керує людина, то коли всередині файлової групи є кілька файлів, то дані по ним розпихує MS SQL Server самостійно (при рівному обсязі файлів - постарається рівномірно). З прикладної точки зору це використовується для розпаралелювання операцій введення-виведення. А з точки зору резервних копій є інший момент. Для дуже великих баз даних в епоху "до SQL 2008" була типовою проблемавиділити безперервне вікно для повної резервної копії, та й диск-приймач для цієї резервної копії міг просто її не вмістив. самим простим способомв цьому випадку було робити резервну копію кожного файлу (або файлової групи) в своє вікно. Зараз, з активним поширенням стиснення резервних копій ця проблема стала менше, але все ж цей прийом можна мати на увазі.
Стиснення резервних копій
В MS SQL Server 2008 року з'явилася супер-мега-ультра можливість. Відтепер і назавжди резервні копії можуть бути компрессированного при формуванні на льоту. Це зменшує розмір резервної копії БД 1С в 5-10 разів. А враховуючи, що зазвичай продуктивність дискової підсистеми є вузьким місцем СУБД, то це дає не тільки зниження вартості зберігання, а й ще потужне прискорення резервного копіювання (хоча і підвищується навантаження на процесори, але зазвичай процесорні потужності цілком достатні на сервері СУБД).
Якщо у версії 2008 ця можливість була тільки для Enterprise редакції (яка коштує дуже дорого), то в 2008 R2 ця можливість віддана в версію Standard, що сильно радує.
Нижче при розборі прикладів налаштування стиснення не розглядаються, але я настійно рекомендую використовувати стиснення резервних копій, якщо немає особливих причин його відключити.
Один файл бекапа - багато нутрощів
Насправді резервна копія це не просто файл, це досить складний контейнер, в якому може зберігатися багато резервних копій. У цього підходу дуже давня історія (я особисто її спостерігаю з версії 6.5), але на поточний момент для адміністраторів "звичайних" баз даних, особливо баз даних 1С, немає будь-яких серйозних причин не використовувати підхід "одна резервна копія - один файл" . Для загального розвитку корисно вивчити можливість складати в один файл декілька резервних копій, але використовувати її швидше за все не доведеться (або якщо і доведеться, то розбираючи завали горе-адміністратора, який цю можливість некваліфіковано використовував).
Кілька дзеркальних копій
У SQL Server є ще одна чудова можливість. Можна резервну копію формувати паралельно в кілька приймачів. Як найпростіший приклад, можна звалювати одну копію на локальний дискі одночасно складати на мережевий ресурс. локальна копіязручна, так як відновлення з неї істотно швидше, віддалена копія зате набагато краще перенесе фізичне знищення основного сервера бази даних.
Приклади систем резервного копіювання
Досить теорії. Пора практикою довести, що вся ця кухня працює.
Налаштування типового резервування сервера через Плани обслуговування (MaintenancePlan)
Цей розділ побудований у вигляді готових рецептів з поясненнями. Цей розділ дуже нудний і довгий за рахунок картинок, тому його можна пропустити.
Користуємося майстром створення плану обслуговування
Налаштування резервування сервера скриптами TSQL, приклади деяких можливостей
Відразу виникає питання, а чого ще треба? Начебто ж тільки що все налаштували і все працює як годинник? Навіщо маятися з усякими скриптами? Плани обслуговування не дозволяють:
- Використовувати дзеркальне резервування
- Використовувати налаштування стиснення відмінні від налаштувань сервера
- Не дозволяє гнучко реагувати на виникаючі ситуації (ніяких можливостей по обробці помилок)
- Не дозволяє гнучко використовувати налаштування безпеки
- Плани обслуговування дуже незручно розгортати (і підтримувати однаковими) на великій кількості серверів (навіть, мабуть, уже на 3-4)
Нижче наведені типові команди резервного копіювання
Повна резервна копія
Повна резервна копія з затиранням існуючого файлу (якщо є) і перевіркою контрольних сум сторінок перед записом. При формуванні резервної копії отсчтітивается кожен відсоток прогресу виконання
BACKUP DATABASE TO DISK = N "C: \ Backup \ mydb.bak" WITH INIT, FORMAT, STATS = 1, CHECKSUM
Разностная резервна копія
Аналогічно - різницева копія
BACKUP DATABASE TO DISK = N "C: \ Backup \ mydb.diff" WITH DIFFERENTIAL, INIT, FORMAT, STATS = 1, CHECKSUM
РКЖТ
Резервна копія журналу транзакцій
BACKUP LOG TO DISK = N "C: \ Backup \ mydb.trn" WITH INIT, FORMAT
дзеркальне резервування
Часто зручно робити відразу не одну резервну копію, а дві. Наприклад, одна може лежати локально на сервері (щоб була під рукою), а друга відразу формується в фізично віддалене і захищене від несприятливих впливів сховище:
BACKUP DATABASE TO DISK = N "C: \ Backup \ mydb.bak", MIRROR TO DISK = N "\\ safe-server \ backup \ mydb.bak" WITH INIT, FORMAT
Важливий момент, який часто не береться: у користувача, від імені якого запускається процес MSSQL Server повинен бути доступ до ресурсу "\\ safe-server \ backup \", інакше копіювання завершиться з помилкою. Якщо MSSQL Server запущений від імені системи, то доступ потрібно давати користувачеві домену "ім'я_сервера $", але краще все-таки коректно налаштувати запуск MS SQL від імені спеціально створеного користувача.
Якщо не вказати MIRROR TO, то це буде не 2 дзеркальних копії, а одна копія, розбита на 2 файли, за принципом чергування. І кожна з них окремо буде марна.
Незважаючи на те, що в наших попередніх матеріалах ми вже торкалися питання резервного копіювання баз Microsoft SQL Server, читацький відгук показав необхідність створення повноцінного матеріалу з більш глибокою обробкою теоретичної частини. Дійсно, виконані з упором на практичні інструкції статті дозволяють швидко налаштувати резервне копіювання, але не пояснюють причини вибору тих чи інших налаштувань. Постараємося виправити цю прогалину.
моделі відновлення
Перед тим як братися за настройку резервного копіювання, слід вибрати модель відновлення. Для оптимального вибору слід оцінити вимоги до відновлення і критичність втрати даних, зіставивши їх з накладними витратами на реалізацію тієї чи іншої моделі.
Як відомо, база даних MS SQL складається з двох частин: власне, бази даних і балки транзакцій до неї. База даних містить призначені для користувача і службові дані на поточний момент часу, лог транзакцій включає в себе історію всіх змін бази даних за певний період, маючи в своєму розпорядженні балкою транзакцій ми можемо відкотити стан бази на будь-який довільний момент часу.
Для використання в виробничих середовищах пропонується дві моделі відновлення: проста і повна. Існує також модель з неповним протоколированием, Але вона рекомендується тільки як доповнення до повної моделі на період великомасштабних масових операцій, коли немає необхідності відновлення бази на певний момент часу.
проста модельпередбачає резервне копіювання тільки бази даних, відповідно відновити стан БД ми можемо тільки на момент створення резервної копії, всі зміни в проміжок часу між створенням останньої резервної копії і збоєм будуть втрачені. В той же час проста схемамає невеликі накладні витрати: вам необхідно зберігати тільки копії бази даних, лог транзакцій при цьому автоматично буде скорочуватися і не росте в розмірах. Також процес відновлення найбільш простий і не займає багато часу.
повна модельдозволяє відновити базу на будь-який довільний момент часу, але вимагає, крім резервних копій бази, зберігати копії балки транзакцій за весь період, для якого може знадобитися відновлення. При активній роботі з базою розмір логу транзакцій, а, отже, і розмір архівів, можуть досягати великих розмірів. Процес відновлення також набагато більш складний і тривалий за часом.
При виборі моделі відновлення слід порівняти витрати на відновлення з витратами на зберігання резервних копій, також слід взяти до уваги наявність та кваліфікацію персоналу, який буде виконувати відновлення. Відновлення при повній моделі вимагає від персоналу певної кваліфікації і знань, тоді як при простої схеми досить буде слідувати інструкції.
Для баз з невеликим об'ємом додавання інформації може бути вигідніше використовувати просту модель з великою частотою копій, яка дозволить швидко відновитися і продовжити роботу, ввівши втрачені дані вручну. Повна модель в першу чергу повинна використовуватися там, де втрата даних недопустима, а їх можливе відновлення пов'язане зі значними витратами.
Види резервних копій
Повна копія бази даних- як випливає з її назви, являє собою вміст бази даних і частина активного балки транзакцій за той час, який формувалася резервна копія (тобто відомості про всі поточні і незавершених транзакцій). Дозволяє повністю відновити базу даних на момент створення резервної копії.
Разностная копія бази даних- повна копія має один істотний недолік, вона містить всю інформацію бази даних. Якщо резервні копії потрібно робити досить часто, то відразу виникає питання неекономного використання дискового простору, так як більшу частину сховища будуть займати однакові дані. Для усунення цього недоліку можна використовувати різницеві копії бази даних, які містять тільки змінилася з часу останнього повного копіювання інформацію.
 Звертаємо увагу, разностная копія - це дані від моменту останнього повногокопіювання, тобто кожна наступна разностная копія містить в собі дані попередньої (але при цьому вони можуть бути змінені) і розмір копії буде постійно зростати. Для відновлення достатньо однієї повної і однієї різницевої копії, зазвичай останньої. Кількість різницевих копій слід вибирати виходячи з приросту їх розміру, як тільки розмір разностной копії зрівняється з розміром половини повної, має сенс зробити нову повну копію.
Звертаємо увагу, разностная копія - це дані від моменту останнього повногокопіювання, тобто кожна наступна разностная копія містить в собі дані попередньої (але при цьому вони можуть бути змінені) і розмір копії буде постійно зростати. Для відновлення достатньо однієї повної і однієї різницевої копії, зазвичай останньої. Кількість різницевих копій слід вибирати виходячи з приросту їх розміру, як тільки розмір разностной копії зрівняється з розміром половини повної, має сенс зробити нову повну копію.
Резервна копія журналу транзакцій- застосовується тільки при повній моделі відновлення і містить копію журналу транзакцій починаючи з моменту створення попередньої копії.

Важливо пам'ятати наступний момент - копії журналу транзакцій ніяк не пов'язані з копіями бази даних і не містять інформацію попередніх копій, тому для відновлення бази вам необхідно мати безперервний ланцюжок копій того періоду, протягом якого ви хочете мати можливість відкочувати стан бази. При цьому момент останнього успішного копіювання повинен бути всередині цього періоду.
Подивимося на малюнок вище, якщо буде втрачена перша копія файлу журналу, то ви зможете відновити стан бази тільки на момент повного копіювання, що буде аналогічно простий моделі відновлення, відновити стан бази на будь-який момент часу ви зможете тільки після наступного різницевого (або повного) копіювання , за умови, що ланцюжок копій журналів починаючи з попереднього копіювання бази і далі буде неперервна (на малюнку - від третього і далі).
Журнал транзакцій
Для розуміння процесів відновлення і призначення різних видів резервних копій слід більш детально розглянути пристрій і роботу журналу транзакцій. Транзакція - це мінімально можлива логічна операція, яка має сенс і може бути виконана тільки повністю. Такий підхід забезпечує цілісність і несуперечність даних при будь-яких ситуаціях, так як проміжний стан операції неприпустимо. Для контролю над будь-якими змінами в базі призначений журнал транзакцій.
При виконанні будь-якої операції в журнал транзакцій додається запис про початок транзакції, кожного запису присвоюється унікальний номер (LSN) з нерозривному послідовності, при будь-якій зміні даних в журнал вноситься відповідний запис, а після завершення операції в журналі з'являється відмітка про закриття (фіксації) транзакції.
 При кожному запуску система аналізує журнал транзакцій і відкочується все незафіксовані транзакції, одночасно з цим відбувається накат змін, які зафіксовані в журналі, але не були записані на диск. Це дає можливість використовувати кешування і відкладений запис, не побоюючись за цілісність даних навіть при відсутності систем резервного живлення.
При кожному запуску система аналізує журнал транзакцій і відкочується все незафіксовані транзакції, одночасно з цим відбувається накат змін, які зафіксовані в журналі, але не були записані на диск. Це дає можливість використовувати кешування і відкладений запис, не побоюючись за цілісність даних навіть при відсутності систем резервного живлення.
Та частина журналу, яка містить активні транзакції і використовується для відновлення даних називається активною частиною журналу. Вона починається з номера, який називається мінімальним номером відновлення (MinLSN).
У найпростішому випадку MinLSN - це номер запису першої незавершеної транзакції. Якщо подивитися на малюнок вище, то відкривши синю транзакцію ми отримаємо MinLSN рівну 321, після її фіксації в запису 324, номер MinLSN зміниться на 323, що буде відповідати номеру зеленої, ще не зафіксованої, транзакції.
На практиці все трохи складніше, наприклад, дані закритої синьою транзакції можуть бути ще не скинули на диск і переміщення MinLSN на 323 зробить відновлення цієї операції неможливою. Для того, щоб уникнути таких ситуації було введено поняття контрольної точки. Контрольна точка створюється автоматично при настанні наступних умов:
- При явному виконанні інструкції CHECKPOINT. Контрольна точка спрацьовує в поточній базіданих з'єднання.
- При виконанні в базі даних операції з мінімальною реєстрацією, наприклад, при виконанні операції масового копіювання для бази даних, на яку поширюється модель відновлення з неповним протоколированием.
- При додаванні або видаленні файлів баз даних з використанням інструкції ALTER DATABASE.
- При зупинці примірника SQL Server за допомогою інструкції SHUTDOWN або при зупинці служби SQL Server (MSSQLSERVER). І в тому, і в іншому випадку буде створена контрольна точка кожної бази даних в екземплярі SQL Server.
- Якщо екземпляр SQL Server періодично створює в кожній базі даних автоматичні контрольні точки для скорочення часу відновлення бази даних.
- При створенні резервної копії бази даних.
- При виконанні дії, що вимагає відключення бази даних. Прикладами можуть служити присвоєння параметру AUTO_CLOSE значення ON і закриття останнього з'єднання користувача з базою даних або зміна параметра бази даних, яка потребує перезапуску бази даних.
Залежно від того, яка подія відбулася раніше, MinLSN буде присвоєно значення або номера запису контрольної точки, або початку найстарішою незавершеною транзакції.
Усічення журналу транзакцій
Журнал транзакцій, як і будь-який журнал, вимагає періодичного очищення від застарілих записів, інакше він розростеться і займе все доступне місце. З огляду на, що при активній роботі з базою розмір логу транзакцій може значно перевищувати розмір бази, то це питання актуальне для багатьох адміністраторів.
Фізично файл журналу транзакцій є контейнером для віртуальних журналів, які послідовно заповнюються у міру зростання балки. Логічний журнал, що містить запис MinLSN є початком активного журналу, що передують йому логічні журнали є неактивними і не потрібні для автоматичного відновлення бази.
 Якщо обрана проста модель відновлення, то при досягненні логічними журналами розміру рівного 70% фізичного файлу відбувається автоматичне очищення неактивній частини журналу, т.зв. усічення. Однак це не призводить до зменшення фізичного файлу журналу, усікаються тільки логічні журнали, які після цієї операції можуть використовуватися повторно.
Якщо обрана проста модель відновлення, то при досягненні логічними журналами розміру рівного 70% фізичного файлу відбувається автоматичне очищення неактивній частини журналу, т.зв. усічення. Однак це не призводить до зменшення фізичного файлу журналу, усікаються тільки логічні журнали, які після цієї операції можуть використовуватися повторно.

Якщо кількість транзакцій велике і до моменту досягнення 70% розміру фізичного файлу не виявиться неактивних логічних журналів, то розмір фізичного файлу буде збільшений.
 Таким чином файл логу транзакцій при простої моделі відновлення буде рости згідно активності роботи з базою до тих пір, поки не буде надійно вміщати всю активну частину журналу. Після чого його зростання припиниться.
Таким чином файл логу транзакцій при простої моделі відновлення буде рости згідно активності роботи з базою до тих пір, поки не буде надійно вміщати всю активну частину журналу. Після чого його зростання припиниться.
При повній моделі неактивну частину журналу можна відсікти до тих пір, поки вона повністю не потрапить в резервну копію. Усічення журналу проводиться за умови, що виконана резервна копія журналу транзакцій, після чого була створена контрольна точка.
Неправильне налаштування резервного копіювання журналу транзакцій при повній моделі здатне привести до неконтрольованого зростання файлу журналу, що часто становить проблему для недосвідчених адміністраторів. Також часто трапляються поради по ручному усіканню журналу транзакцій. При повній моделі відновлення робити цього не слід категорично, так як тим самим ви порушите цілісність ланцюжка копій журналу і зможете відновити базу тільки на момент створення копій, що буде відповідати простої моделі.
У цьому випадку саме час згадати те, про що ми говорили на початку статті, якщо витрати на повну модель перевищують витрати на відновлення слід віддати перевагу простій моделі.
Проста модель відновлення
Тепер, після отримання необхідного мінімуму знань, можна перейти до більш докладного розгляду моделей відновлення. Почнемо з простої. Припустимо, на момент збою у нас є одна повна і дві різницеві копії:
 Резервне копіювання виконувалося раз на добу і остання копія була створена вночі з 21-го на 22-е. Збій відбувається ввечері 22-го до створення чергової копії. У цьому випадку нам буде потрібно послідовно відновити повну і останню різницеві копії, при цьому дані за останній робочий день буде втрачено. Якщо з яких-небудь причин копія від 21-го також виявиться пошкоджена, то ми можемо відновити попередню копію, втративши ще день роботи, в той же час пошкодження копії за 20-е число ніяк не завадить успішно відновити дані на вечір 21-го, при наявності відповідної копії.
Резервне копіювання виконувалося раз на добу і остання копія була створена вночі з 21-го на 22-е. Збій відбувається ввечері 22-го до створення чергової копії. У цьому випадку нам буде потрібно послідовно відновити повну і останню різницеві копії, при цьому дані за останній робочий день буде втрачено. Якщо з яких-небудь причин копія від 21-го також виявиться пошкоджена, то ми можемо відновити попередню копію, втративши ще день роботи, в той же час пошкодження копії за 20-е число ніяк не завадить успішно відновити дані на вечір 21-го, при наявності відповідної копії.
Повна модель відновлення
Розглянемо аналогічну ситуацію, але із застосуванням повної моделі відновлення. Резервні копії у нас також робляться щодоби, за принципом повна + різницеві, а також кілька разів на добу копіюється лог транзакцій.
 Процес відновлення в цьому випадку буде більш складний. Перш за все потрібно створити вручну резервну копію заключного фрагмента журналу (показана червоним), тобто частина журналу з моменту минулого створення копії і до аварії.
Процес відновлення в цьому випадку буде більш складний. Перш за все потрібно створити вручну резервну копію заключного фрагмента журналу (показана червоним), тобто частина журналу з моменту минулого створення копії і до аварії.
Якщо цього не зробити, то відновити базу можна буде тільки до стану на момент створення останньої копіїжурналу транзакцій.
При цьому пошкодження файлу копії журналу за попередній день не завадить нам відновити актуальний стан бази, але обмежить нас моментом створення останньої копії, тобто поточними цілодобово.
Потім послідовно відновлюємо повну і разностную копію і ланцюжок копій журналу, створену після останнього резервного копіювання, останньої відновлюємо копію заключного фрагмента журналу, що дасть нам можливість відновити базу прямо на момент аварії чи довільний, що передував йому.
Якщо остання разностная копія буде пошкоджена, то у випадку з простою моделлю це призведе до втрати ще одного робочого дня, повна модель дозволяє відновити передостанню копію, після чого потрібно буде відновити весь ланцюжок копій балки транзакцій від моменту передостанній копії і до збою. Глибина відновлення залежить тільки від глибини безперервного ланцюжка логів.
З іншого боку, якщо одна з копій балки транзакцій буде пошкоджена, скажімо, передостання, то відновити дані ми зможемо тільки на момент останньої резервної копії + період в непошкодженій ланцюжку копій журналів. Наприклад, якщо журнали робилися в 12, 14 і 16 годин і пошкоджений журнал, створений в 14 годин, то в своєму розпорядженні добової копією ми зможемо відновити базу до моменту закінчення безперервного ланцюжка, тобто До 12 години.